Different generative laws
Weather and energy often contain physical structure and seasonal regularities. Finance is noisy, stochastic, and regime-dependent. A single universal prior can average incompatible assumptions.
Position Paper · ICML 2026
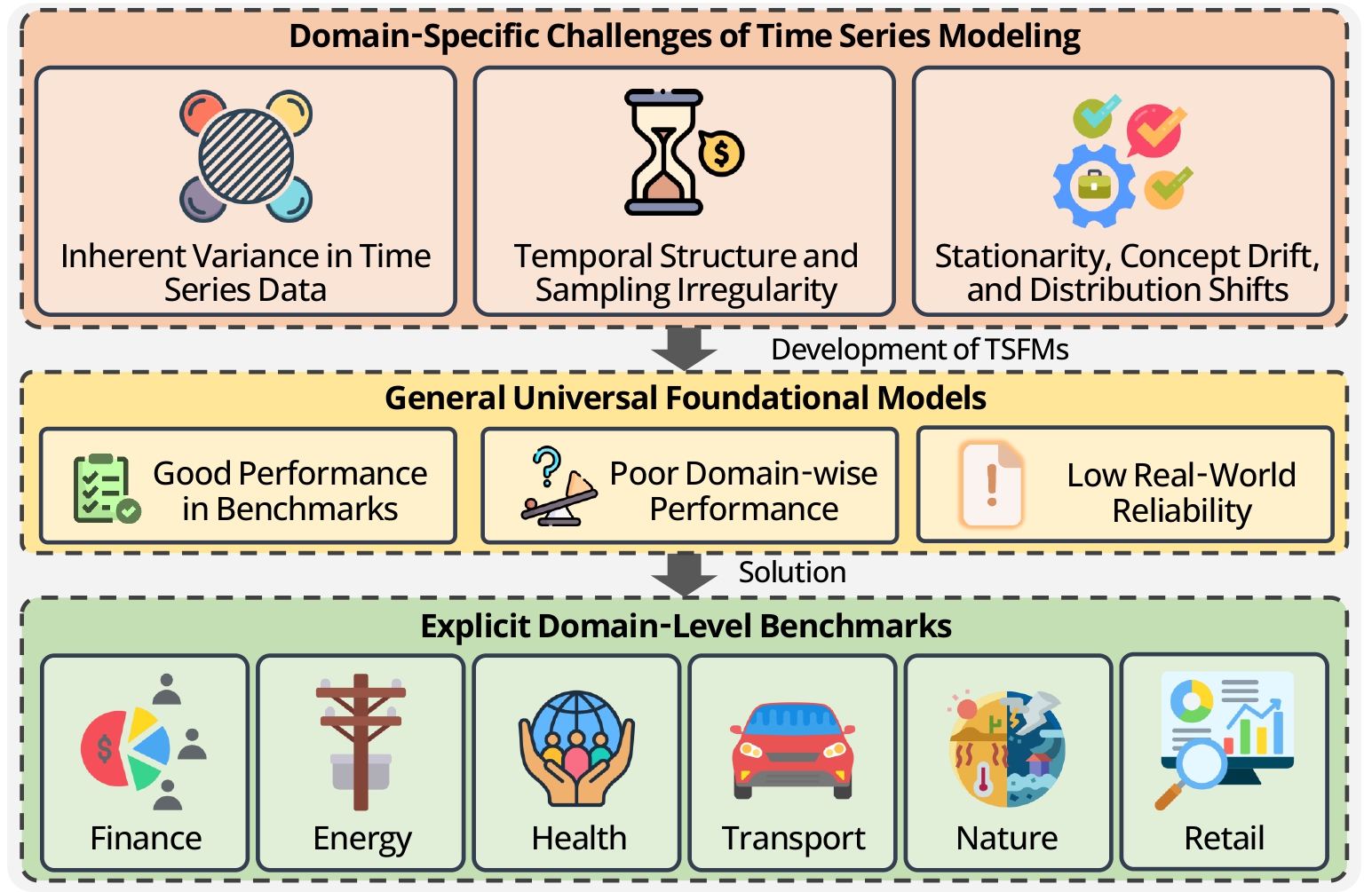
Universal time-series foundation models can look strong on pooled leaderboards while failing inside specific deployment domains. This project argues for explicit domain-stratified evaluation to reveal those failures across health, finance, energy, nature, transport, and retail, where differences in sampling, noise, seasonality, and distribution shift can change which model performs best.
Abstract
Time-series foundation models have shown strong benchmark performance, but common benchmark suites pool datasets from unevenly represented domains. This can hide whether a model is actually reliable in healthcare, finance, energy, retail, transport, or environmental forecasting. The paper evaluates seven TSFMs across 72 datasets from six domains and finds substantial cross-domain variability, showing that global scores are not enough for trustworthy model selection.
Core argument
Weather and energy often contain physical structure and seasonal regularities. Finance is noisy, stochastic, and regime-dependent. A single universal prior can average incompatible assumptions.
Clinical data may be irregular, multi-rate, and informative when missing. High-frequency finance is event-driven. Fixed patching and uniform-grid assumptions can break under these settings.
Covariate shift, concept drift, volatility bursts, patient-specific trajectories, and seasonal recalibration create domain-specific failure modes that pooled metrics can miss.
Empirical validation
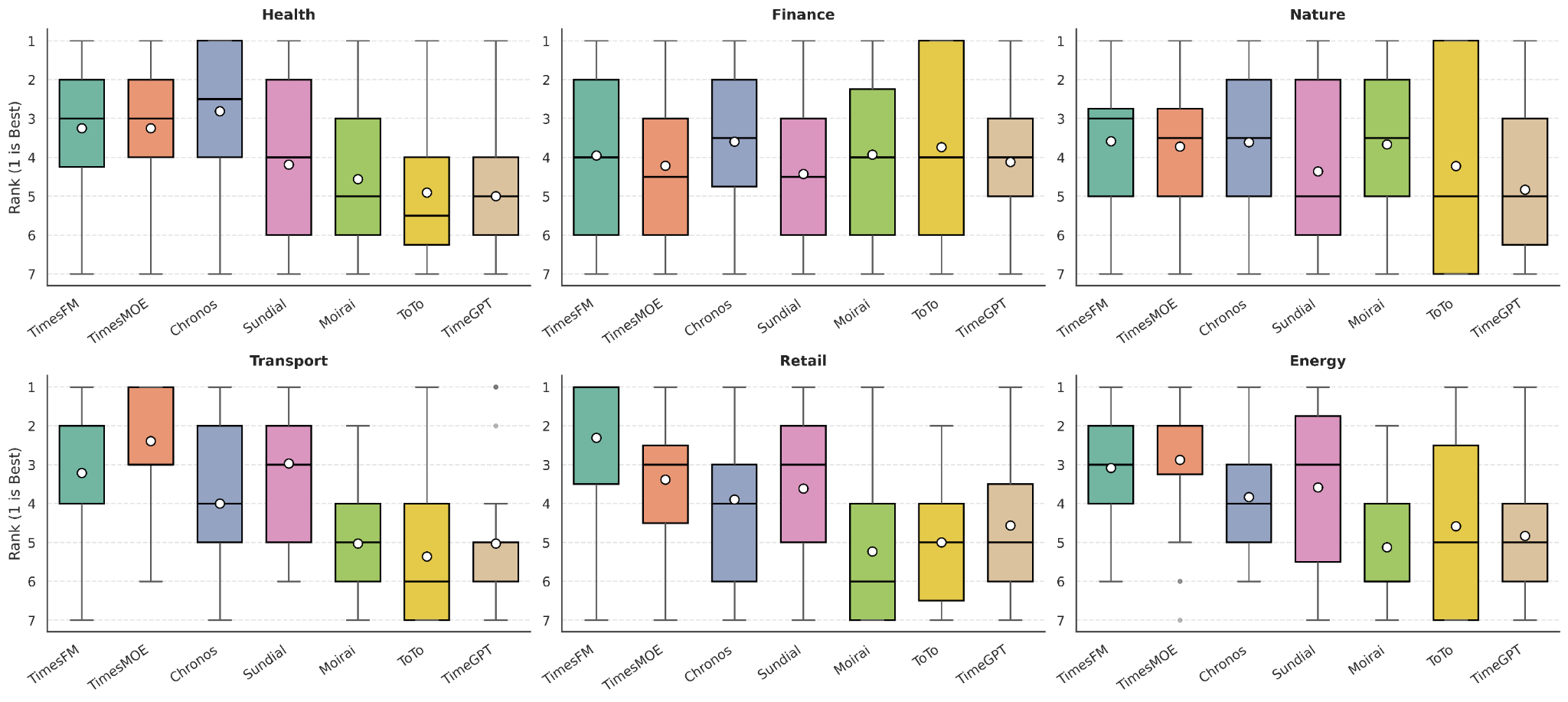
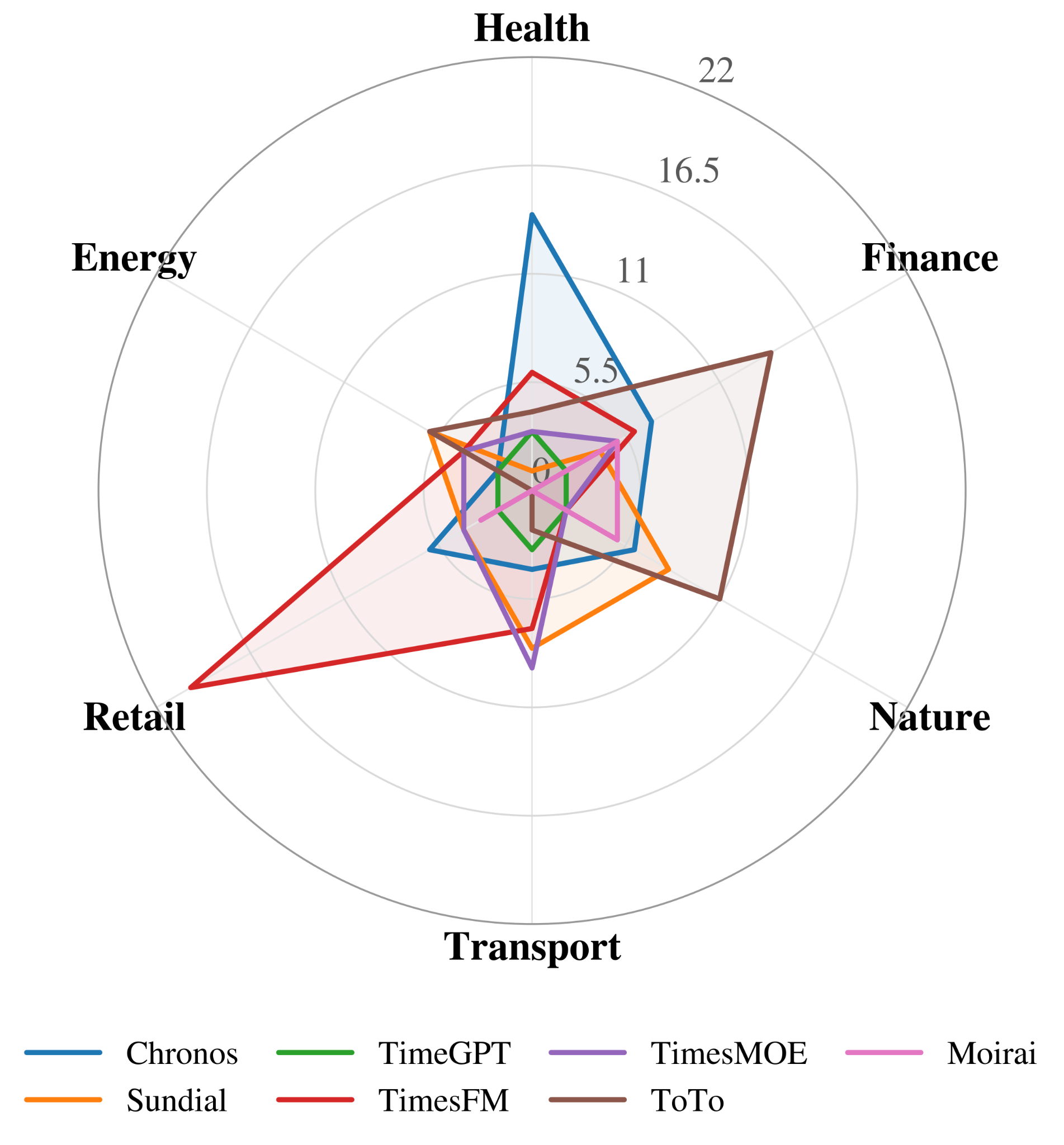
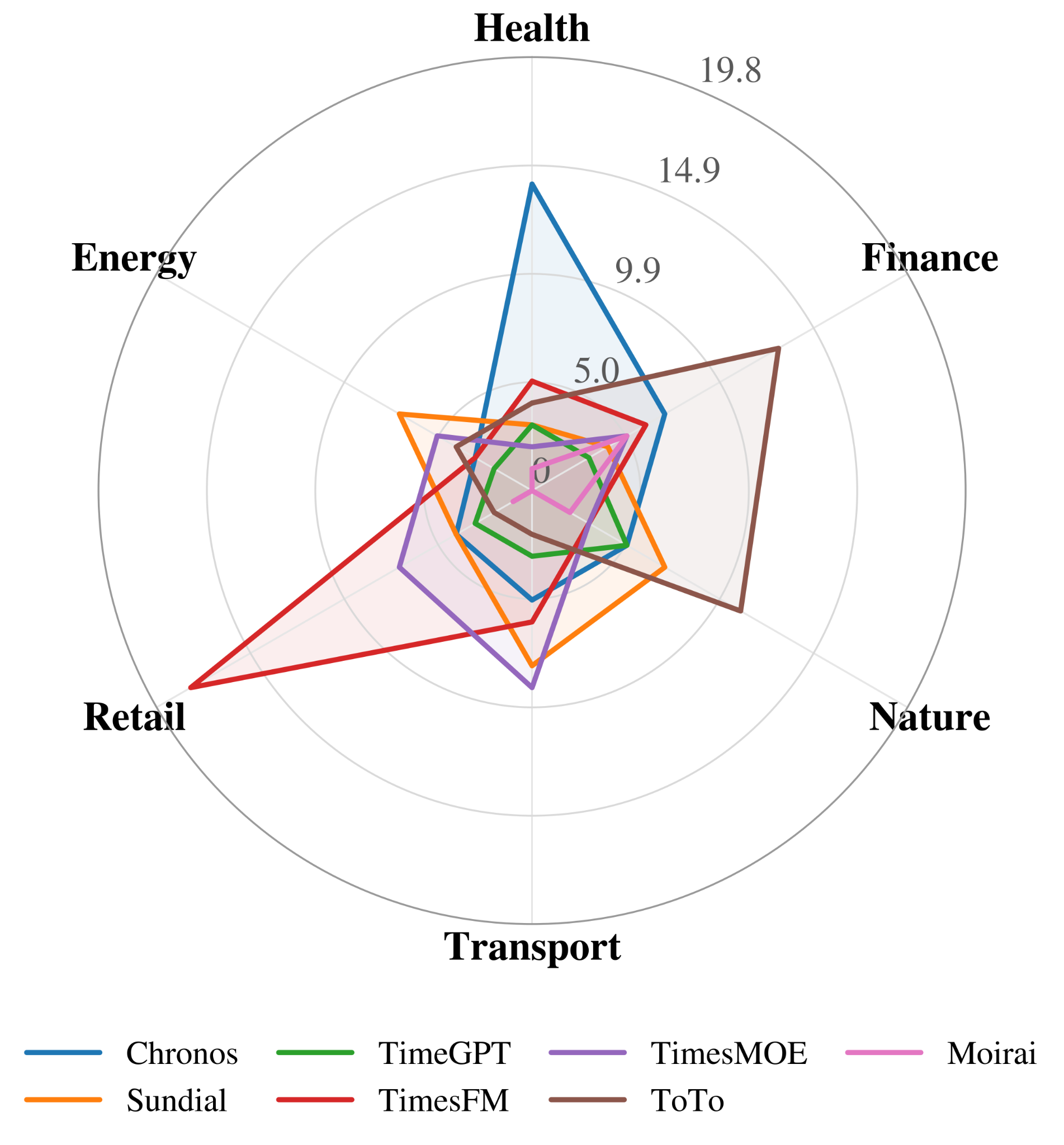
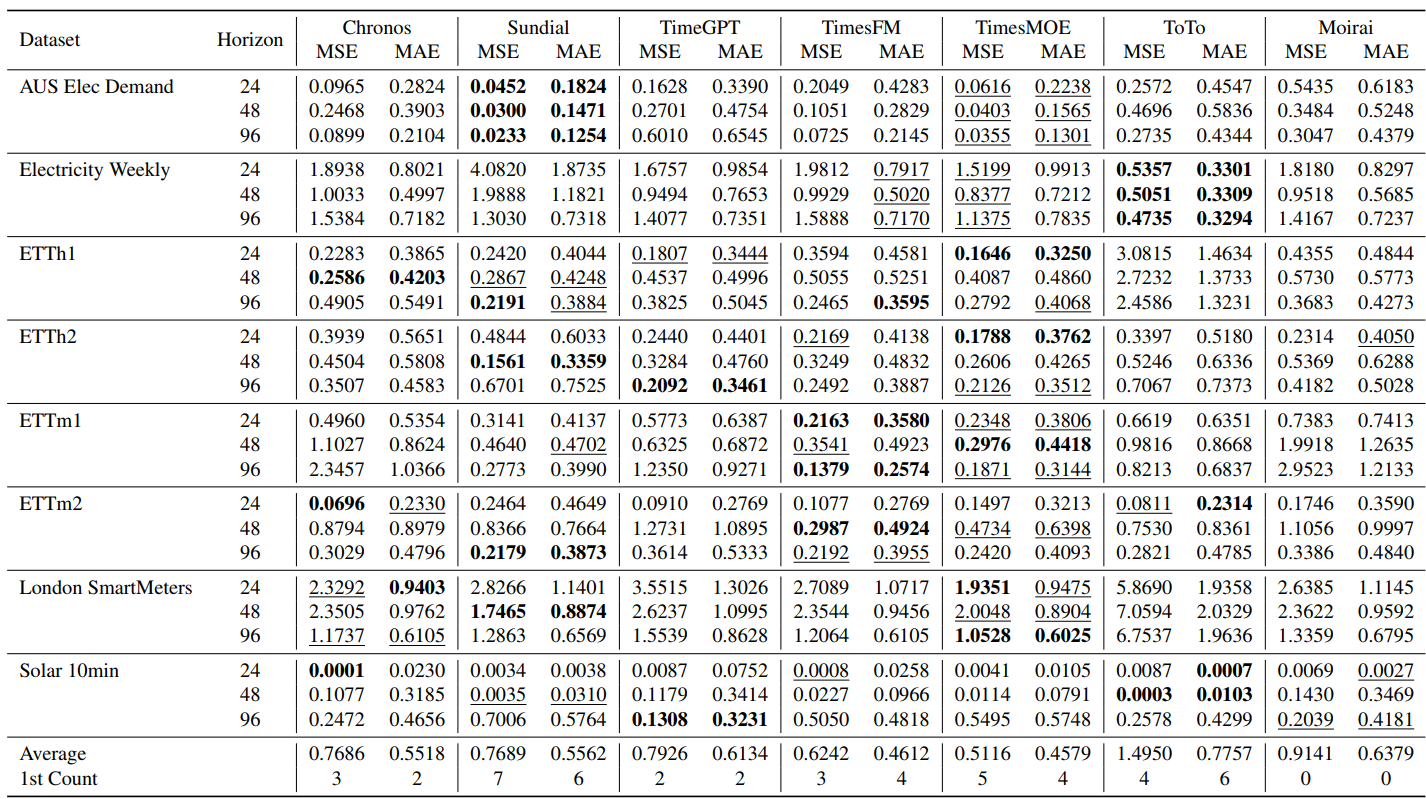
The same model can be strong in one domain and weak in another. These figures expose rank reversals and domain-specific win patterns that a single leaderboard average would flatten.

Benchmark coverage
Existing benchmarks are domain-imbalanced, so pooled scores can hide weak performance in underrepresented areas.
Detailed energy-domain results across datasets, horizons, models, MSE, MAE, average scores, and first-place counts.
Call to action
Our results suggest a shift away from only reporting pooled global scores. Domain-stratified benchmarking can reveal where TSFMs succeed, where they fail, and when domain-aware modeling is necessary.
Benchmarks such as Monash, GIFT-Eval, and TSFM-Bench already contain multiple domains. The key change is to report results by domain instead of hiding failures behind pooled averages.
Specialized models for medical irregularity, missingness, financial non-stationarity, or other domain-specific challenges should be compared directly against universal TSFMs under standardized domain-level benchmarks.
Practitioners need a way to predict which source domains help or harm target domains. Useful transfer frameworks should consider sampling frequency, stationarity, causal structure, and drift behavior.